이전 강의에서 웨이블릿 변환을 알아보았습니다. 이때, 특정 시점에서 변화되는 양을 정량적으로 찾아야 되는데 이때 변화되는 시점을 Change Point Analysis(CPA) 기법을 사용할 것입니다.
1. CPA 개념
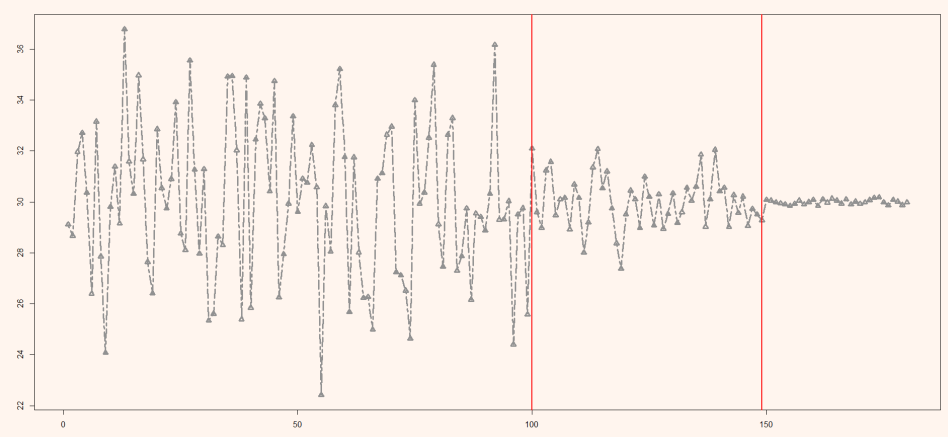
수학적인 것은 다음 강의에서 설명 드리겠으며, 이번 포스팅에서는 개념적으로 CPA를 이해해 보겠습니다. 아래는 이전 강의에서의 CWT(Continuous Wave Transform) 결과인데 빨간색 화살표처럼 어디가 시작이고 끝인지를 알아야겠지요. 이를 찾기 위해 CPA 기술이 필요하게 됩니다.
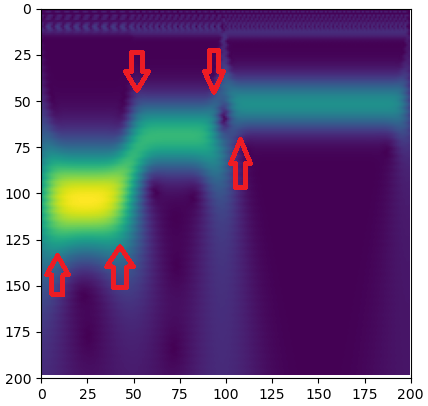
이때, CPA 접근방법은 평균적 또는 분산적 접근 방법이 있습니다. 이번 포스팅에서 평균적 그리고 분산적 접근 방법을 간단히 알아보도록 하겠습니다.
2. 평균적 CPA 접근 방법
(1) C언어적 접근 방법 : 필자는 C언어를 잘 쓰지 않기 때문에 아래 플라식틱 코드라는 분의 오픈소를 가져와 봤습니다. 이를 어떻게 해석하는지에 대한 초점으로 알아보시죠.
## mean change detection ##
library(changepoint)
n = c(100,50,30)
mean = c(30, 20, 50)
sd = c(1,1,1)
X = c();
for (i in 1:length(n)) {
x = rnorm(n[i],mean[i],sd[i])
X = c(X,x)
}
par(bg='seashell')
plot(X, type="o", lty=sample(1:6,1), col=sample(colors(),1), pch=sample(0:20,1), lwd=sample(2:5,1), ylab="", xlab="")
cp = slot( cpt.mean(X, method="BinSeg"), "cpts" ); cp=cp[which(cp!=length(X))]
abline(v = cp, col="red", lwd=2)
##============================================================##
[출처] R : change point analysis|작성자 플라스틱 코드우선 위의 것을 이해하기 위해서 rnorm을 알아보도록 합니다.
rnorm은 난수 함수를 의미합니다. r은 random의 약자이며, 난수함수는 정규분포함수의 변수에 해당하는 값을 임의로 생성해 주는 함수입니다. 즉, 정규분포 값을 임의로 생성해 준다고 생각하시면 될 것 같습니다.
자 그러면 파이썬에서 nnorm함수를 사용할 때 아래와 같습니다.
rnorm(데이터 개수, 평균, 분산) 이렇게 넣으면 됩니다. 만약 rnorm(5, mean=100, sd=5)의 값을 넣으면 평균이 100에서 분산이 5를 넘기지 않는 5개의 데이터가 출력이 됩니다. 간단하지요. 자 그러면 다시 위의 코드해석으로 넘어가 봅시다.
우선 임의의 신호를 아래와 같은 조건으로 생성 할 것입니다.
(1) n = c(100, 50, 30) : n에다가 c라는 함수를 인스턴스화시키는데 이때, c는 100, 50, 30이라는 값이 들어 있고 이는 데이터 개수로 사용 될 것입니다.
(2) mean = c(30, 20, 50) : 여기서 c는 평균으로 사용될 것이며, mean에 인스턴스화됩니다.
(3) sd = c(1, 1, 1) : 여기서 c는 분산으로 사용될 것이며, sd에 인스턴스화 됩니다.
(4) 각 c의 열에 있는 값들과 rnorm 함수를 이용해 길이 100의 평균 30 그리고 분산이 1인 신호와 길이 50 평균이 20 분산이 1인 신호 마지막으로 길이 30 평균이 50 분산이 1인 신호를 X에 순차적으로 붙이는 코드입니다. 이렇게 붙이면 임의의 신호가 생성됩니다.
그리고 위의 신호에서 평균이 변하는 지점을 찾아야겠지요. 이때 사용된 함수는 cpt.mean이라는 함수입니다. 이 함수는 연산 구간의 평균이 가장 유의하게 변화되는 지점을 감시합니다.
코드에 적힌 부분은 Binary Segmentation 방법으로, 전체 트렌드 중 가장 평균이 유의하게 변화하는 지점을 찾은 뒤, 그 지점을 전 후로 다시 평균이 유의하게 변하는 구간을 찾습니다. 더 이상 평균의 변화가 없을 때까지 변화 지점을 2, 4, 6 이런 식으로 늘리며 찾게 됩니다. 정규분포를 가정하며, 두 분포가 얼마나 상이한지를 판단하는 모수적(parametic) 방법으로 mean change가 발생한 지점을 빠르게 찾습니다.
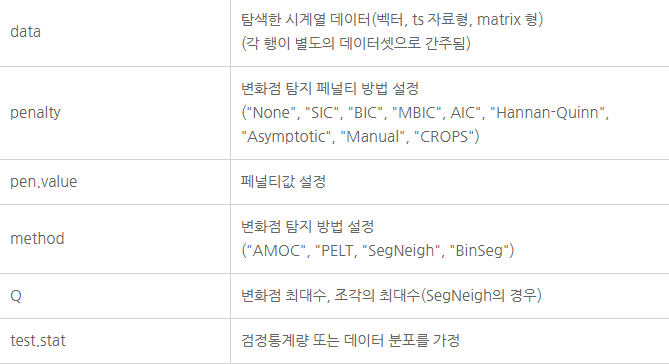
이때, 사용하는 옵션은 AOMC, PELT, SegNeig, BinSeg의 네 가지입니다. AOMC는 단일 변화점(single changepoint)을 설정하고 PELT와 Segneig는 여러 개의 변화점(multiple changepoint)을 찾습니다. 이때, PELT는 정확고 빠르지만 모든 분포에 사용될 수 없는 단점이 있습니다.
BinSeg는 Binary Segmentation 변화점을 설정합니다. 이 Binary Segmentation이 앞서 설명한 공간을 2개씩 잘라가며 변화점을 찾는 방법입니다. 이런 식으로 넣을 수 있는 값들은 아래 그림과 같습니다.
그리고 slot 함수에서 cpt.mean이 완료되면 cpts라는 함수를 사용하는데 이는 평균의 변화가 발생할 시점을 벡터로 알아보는 함수입니다. 즉 어떤 시간/시점/샘플에서 변화가 발생한 지를 찾아내게 됩니다. cpts 함수를 이용하여 변화는 지점을 알았기 때문에 abline함수를 이용하여 지점을 표시합니다.
그림으로 살펴봅시다.
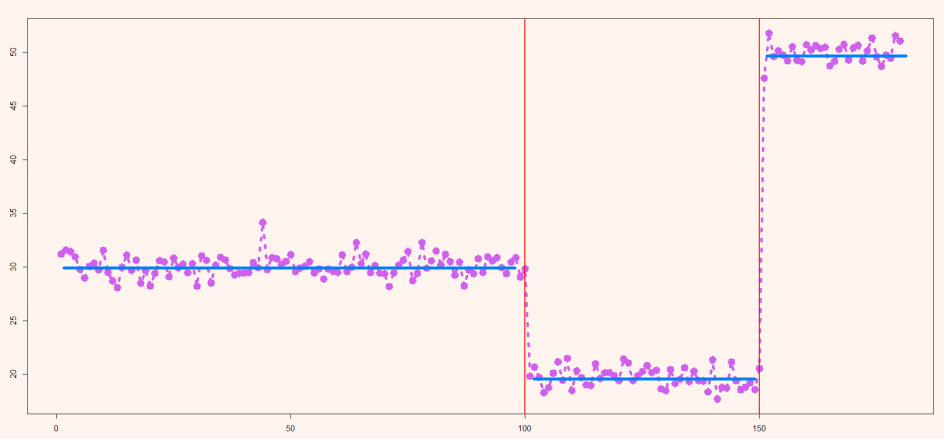
위의 값을 보면 평균적으로 변화하는 지점에서 변화지점을 정확히 예측하는 것을 볼 수 있습니다.
(2) Python적 접근방법
아래는 파이썬 코드입니다. 여러 군데에서 짜깁기 한 건데 생각보다 고생을 했네요.
import numpy as np
import matplotlib.pyplot as plt
#make this example reproducible
np.random.seed(1)
data4 = []
#generate array of 200 values that follow normal distribution with mean=5 and sd=2 .tolist()
data1 = np.random.normal(loc=30, scale=1, size=100).tolist() #loc 평균, sacle 분산, size 셈플길이
data2 = np.random.normal(loc=20, scale=1, size=50).tolist() #loc 평균, sacle 분산, size 셈플길이
data3 = np.random.normal(loc=50, scale=1, size=30).tolist() #loc 평균, sacle 분산, size 셈플길이
data4.append(data1)
data4.append(data2)
data4.append(data3)
data4 = data1 + data2 + data3
#create histogram to visualize distribution of values
#plt.hist(data4, bins=30, edgecolor='black')
#plt.show()
# plt.plot(data4, 'r--')
# plt.show()
import ruptures as rpt
import changefinder
points=np.array(data4)
print(points)
# Changepoint detection with the Pelt search method
model = "rbf"
algo = rpt.Pelt(model=model).fit(points)
result = algo.predict(pen=10)
rpt.display(points, result, figsize=(10, 6))
plt.title('Change Point Detection: Pelt Search Method')
plt.show()
# Changepoint detection with the Binary Segmentation search method
model = "l2"
algo = rpt.Binseg(model=model).fit(points)
my_bkps = algo.predict(n_bkps=2)
# show results
rpt.show.display(points, my_bkps, figsize=(10, 6))
plt.title('Change Point Detection: Binary Segmentation Search Method')
plt.show()
# Changepoint detection with window-based search method
model = "l2"
algo = rpt.Window(width=40, model=model).fit(points)
my_bkps = algo.predict(n_bkps=10)
rpt.show.display(points, my_bkps, figsize=(10, 6))
plt.title('Change Point Detection: Window-Based Search Method')
plt.show()
# Changepoint detection with dynamic programming search method
model = "l1"
algo = rpt.Dynp(model=model, min_size=3, jump=5).fit(points)
my_bkps = algo.predict(n_bkps=10)
rpt.show.display(points, my_bkps, figsize=(10, 6))
plt.title('Change Point Detection: Dynamic Programming Search Method')
plt.show()
#CHANGEFINDER PACKAGE
f, (ax1, ax2) = plt.subplots(2, 1)
f.subplots_adjust(hspace=0.4)
ax1.plot(points)
ax1.set_title("data point")
#Initiate changefinder function
cf = changefinder.ChangeFinder()
scores = [cf.update(p) for p in points]
ax2.plot(scores)
ax2.set_title("anomaly score")
plt.show()
내용은 위와 동일합니다. 단, anomaly 방법이 추가되어 있는데 이 부분은 머신러닝에서 자주 쓰이며, 기타 다른 포스팅을 참조하시기 바랍니다. 생각보다 설명할 것들이 너무 많네요.
위의 그림들 중 앞서 설명드린 Binary Segmentation search method 기법을 적요한 것입니다. c언어와 동일한 값이 나오지요?
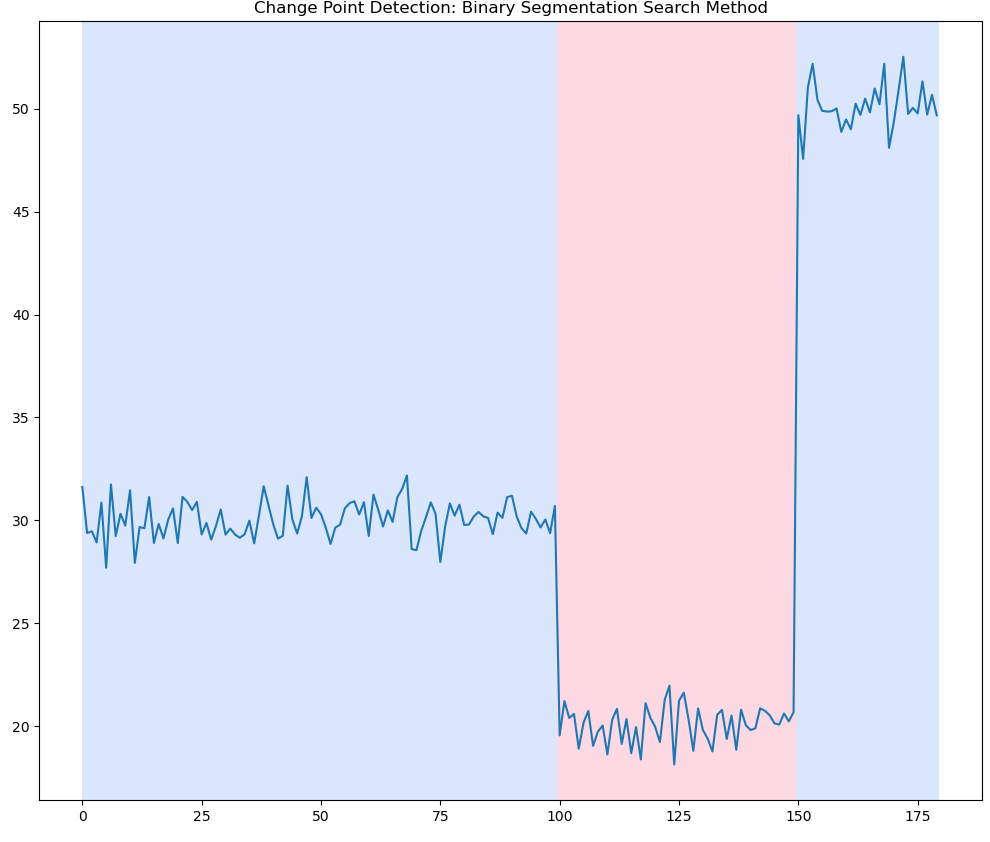
아래는 anomaly기법인데 특정 변화지점에서 anomaly score가 가장 높아지는 것을 확인하실 수 있습니다.
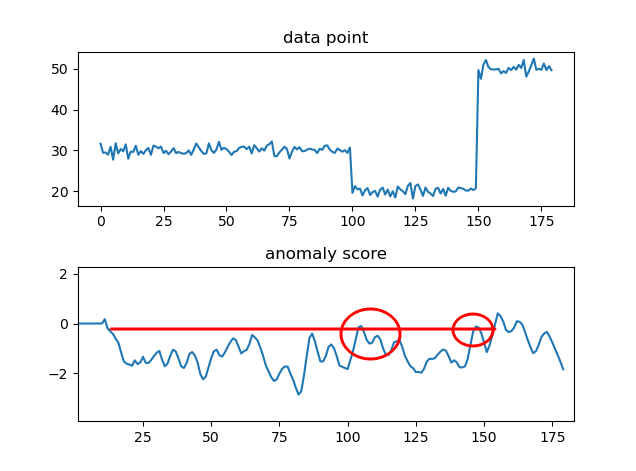
3. 분산적 CPA 접근 방법
분산적 접근방법은 cpt.var만 다르고 위와 동일합니다.
## sd change detection ##
library(changepoint)
n = c(100,50,30)
mean = c(30, 30, 30)
sd = c(3,1,0.1)
X = c();
for (i in 1:length(n)) {
x = rnorm(n[i],mean[i],sd[i])
X = c(X,x)
}
par(bg='seashell')
plot(X, type="o", lty=sample(1:6,1), col=sample(colors(),1), pch=sample(0:20,1), lwd=sample(2:5,1), ylab="", xlab="")
cp = slot( cpt.var(X, method="BinSeg"), "cpts" ); cp=cp[which(cp!=length(X))]
abline(v = cp, col="red", lwd=2)
[출처] R : change point analysis|작성자 플라스틱 코드그래프를 그려보시면 아래와 같습니다. 분산이 변화되는 지점을 정확히 파악합니다.
자 여기까지가 변화지점 탐지 방법이었습니다. 이 기법은 어디에나 쓰일 수 있습니다. 심지어 주식에서도 급격히 변화되는 지점을 찾아 도망가거나 매수할 수 있는 알고리즘으로 변형할 수 있겠지요??
얼마나 좋은 수학적 알고리즘입니까. 이렇게 확률적으로 자동매매를 하실 수 있습니다.
그리고 다음 장에서는 엘보우 기법을 한번 알아보도록 하겠습니다.
'대학 과목 > 빔 포밍(Beam Forming)' 카테고리의 다른 글
| Elbow method : 변화 지점 탐지 시 최적의 군집 수 구하기(K-means) (12) | 2023.05.16 |
|---|---|
| 연속 웨이블릿 변환(Continuous Wavelet Transform) 스케일과 주파수의 관계 그리고 예제 (20) | 2023.05.07 |
| 웨이블릿(Wavelet) 변환(Transform) 상세 설명(그림 참조) (28) | 2023.05.07 |
| 웨이블릿(Wavelet) 변환의 개념(수식 없음) (7) | 2023.05.05 |
| 빔포밍(Beam Forming)의 개념과 이를 위한 구면좌표계(Spherical Coordinate) (20) | 2023.03.27 |



