이번에는 Tracking의 정확도 관점에서 센서를 어떻게 배치 또는 선택하는지 알아보겠습니다. 우선 이전 포스팅 관련하여 잠깐 복습을 진행하도록 하겠습니다.
1. 이전 포스팅 복습
이전 포스팅에서는 센서가 고정돼있거나 움직일 경우 어떻게 센서를 그룹화하고 배치 또는 활성/비활성화하는지에 대하여 알아보았습니다. 특히 센서가 고정되어 있을 때는 lenear programing과 DSC(Disjoint Set Cover) 조건에서 NP-complete임을 증명하고 휴리스틱(경험) 기반에 의해 근사화하는 것을 알아보았죠. 그리고 센서가 움직일 경우에는 Bidding protocol을 사용하여 커버리지의 빈틈을 채우는 방법을 알아보았습니다.
이번 포스팅에서는 Tracking과 Localization 관점에서 센서를 어떻게 활성/비활성화 하는지 알아보겠습니다. 본 논문은 상당히 지루하지만 깊이가 얕아 진입장벽이 낮습니다.
2. Target Tracking And Localization Schemes
이 세션에서는 목표물의 추적 및 위치 추정을 위해 센서들을 어떻게 선택해야 하는지에 대하여 설명되어 있습니다. 이때 아래의 3가지 범주에서 고려되어집니다.
(1) 엔트로피 기반 설루션 : 측정 엔트로피를 최소화하도록 설정
(2) 동적 정보 기반 솔루션 : 동적으로 수집된 정보에 기반하여 정보 획득을 최대로 하는것이 목표
(3) 평균 제곱 오차 기반 솔루션 : 측정값의 평균 제곱 오차를 최소화하는 것이 목표
자 위의 3가지를 한번 살펴보도록 합니다.
(1) 엔트로피 기반 솔루션
엔트로피라는 것은 불확실성의 척도(무질서도)를 의미합니다. 측정값의 엔트로피가 작을수록 정확성이 높아진다거나 안정화된다고 생각하시면 됩니다.
흔히들 엔트로피 증가법칙이라고 많이들 사용하는데 이는 변화를 유발하는 온도차나 물질 구분이 없어지면서 더 이상의 변화가 일어나지 않는 상태를 뜻합니다. 조금 어려우니 우선적으로 간단히 엔트로피에 대하여 알아보도록 하겠습니다.
- 볼츠만의 엔트로피
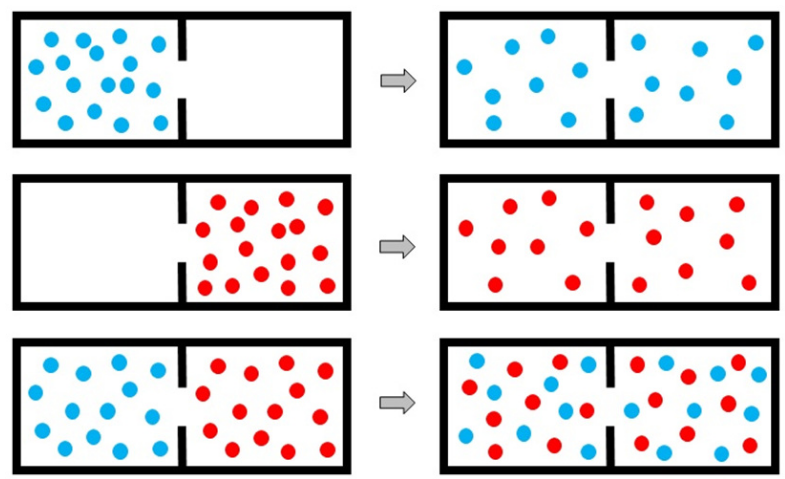
볼츠만은 기체 분자의 확률 또는 경우의 수를 써서 엔트로피를 표현하였습니다. 많은 수의 기체 분자들은 한 곳에 몰려 있지 않고 골고루 흩어지죠. 마치 아래 그림처럼요. 이처럼 질서 정연하던 것이 무질서(disorder) 해지는 것을 볼 수 있습니다. 이때, 볼츠만은 기체 분자 거동에서 일어날 수 있는 경우의 수에 로그를 취한 값으로 정의했습니다. 즉, 어느 정도 증가하다가 더 이상 변하지 않는 "죽음"의 상태로 간다는 것이죠. 또한 로그를 취함으로 써 곱셈으로 늘어나는 경우의 수 들을 덧셈으로 바꿔 주는 위함도 있습니다. 거듭제곱에 따라 증가하던 경우의 수를 정보량을 선형적인 관계로 바꿀 수 있습니다.
자 다시 돌아와 논문을 리뷰하도록 하겠습니다.
Ertin과 Liu 등은 미래 상태와 현재 노드 측정값 간의 상호 정보를 이용하여 다양한 센서 정보를 획득 결정하게 됩니다. 이때 센서 선택을 위해 탐욕 알고리즘을 사용합니다. 탐욕 알고리즘이란 매 순간마다 해결책을 선택하는 알고리즘입니다. 특히 the most obvious & immediate benefit를 가지는 방법을 선택하는데 엄청난 양의 계산양이 발생할 수 있습니다. 또한 눈앞의 최적의 이익만 좇다 보면 최종 결론으로 도달 시 그 답이 최적의 답이라는 보장이 없습니다. 탐욕알고리즘이 문제를 해결하는 방법은 아래와 같습니다.
- 선택 절차(Selection Procedure) : 현재 상태에서의 최적의 해답을 선택
- 적정성 검사(Feasibility Check) : 선택된 해가 문제의 조건을 만족하는지 검사
- 해답 검사(Solution Check) : 원래의 문제가 해결되었는지 검사하고 해결되지 않으면 선택 절차로 돌아간다.
그리고 이 알고리즘을 사용하려면 아래 조건이 필요합니다.
- 탐욕적 선택 속성(Greedy Choice Property) : 앞의 선택이 이후의 선택에 영향을 주지 않는다.
- 최적 부분 구조(Optimal Substructure) : 문제에 대한 최종 해결 방법은 부분 문제에 대한 최적 문제 해결방법으로 구성된다.입니다.
자 다시 리뷰로 돌아오겠습니다. 탐욕적 선택 시마다 목표물의 위치 분포의 엔트로피 감소가 최대화될 것으로 예상되는 센서와 관측된 값을 선택하게 됩니다. 새롭게 측정된 관측값은 재귀적인 베이시안 추정 기법을 사용하여 타깃 위치 분포를 결정하는 데 사용됩니다. 이때 가장 중요한 것은 필요한 센서 이상을 사용하지 않으면서 원하는 엔트로피 수준에 도달하는 것입니다.
이 방식은 문재점은 다양한 후보 센서들에 대한 예상 엔트로피 감소를 어떻게 효과적으로 평가하는 것입니다. 즉, 실제 다양한 센서로부터 데이터를 획득하지 않고서는 정확한 결정이 어렵습니다. 또한 이방식은 탐욕 알고리즘을 사용하므로 선택 결정을 단일 노드에서 수행하므로 중앙 집중식입니다. 이는 확장성이 떨어지며, 통신 부하가 매우 크므로 많은 시나리오네는 적용하기 적합하지 않습니다.
Wang 등은 계산 비용이 많이 드는 상호 정보를 사용하여 최적 설루션을 찾는 대신, 보다 효율적인 하위 최적 솔루션을 제공하는 휴리스틱 기법을 제안하였습니다. 이는 사전에 목표물 위치에 대한 확률 분포와 일련의 센서 위치 및 모델이 주어진 경우 타겟 위치 분포, 선택된 센서 관측값의 집합의 불확실성이 최대한으로 감소시킬 수 있도록 정보성 센서를 선택합니다. 제안된 휴리스틱 기법은 한 번에 한개의 센서를 추가하며 타겟 위치 분포의 엔트로피를 감소시키는데, 이 방법 역시 중앙집중식이므로 확장 가능성에 제안이 있습니다.
(2) 동적 정보 주도 솔루션
Zhao 등은 센서 j개를 선택하여 목표물 위치 정확도를 가장 높게 하면서 비용을 최소화할 수 있는 방법을 고려하였습니다. 이는 정보 획득과 비용을 어떻게 최적화할 수 있는지에 대한 고민과 같습니다. 이 방법의 목표는 아래와 같습니다.
- 탐지 품질
- 추적 품질
- 확장성
- 생존성
- 자원 사용 개선
제안 방법은 단일 센서(리더 센서)를 선택하여 우선적으로 활성화시킵니다. 초기 선택은 목표물의 예측되는 위치를 고려하여 알고리즘이 가동됩니다. 그 이후로는 목표물에 대한 필요한 측정값을 수집한 후 리더 센서는 정보성이 높다고 믿는 다음 노드를 선택하고 그 측정 값을 전달합니다. 그리고 선택된 노드가 리더가 되며, 다시 이 행위를 반복하게 됩니다.
다음 리더를 결정할 때, 현재 리더는 후보 센서의 정보 유틸리티 값을 고려합니다. 정보 유틸리는 추적에 대한 다양한 정보라고 하였지요. 즉, 센서의 위치, 모덜 리티, 신뢰 상태와 같은 정보에 기반됩니다. 이때, 저자는 엔트로피를 기반으로 한 정의와 거리 측정 기반으로 한 정의 2가지를 고려하였습니다. 엔트로피 기반 정의의 경우에는 수학적으로 더 정확하지만, 실제 환경에서 계산하기가 매우 어렵습니다. 이는 어떤 결정을 내리기 전에 센서의 측정값을 알아야 되기 때문입니다. 거리기반 측정을 사용하면, 리더 노드는 추정된 타깃 위치로부터의 후보 노드들 유틸리티를 측정합니다. 직관적이며 간단하겠지요. 하지만 이 방법의 단점은 첫 번재 리더의 선택이 전체적인 추적 품질에 영향을 미치는 것입니다. 첫 번째 리더 센서가 목표물과 멀리 떨어져 있을 경우, 예측 오류로 인해 전체적인 추적 품질저하가 나타나거나 프로세스가 실패할 수 있습니다. 또한 이방법의 경우 한 번에 하나의 센서만 선택하므로 에너지 측면에서 효율적일 수 있지만, 다양성을 보장하지 못한다는 단점이 있습니다. 여러 개를 병렬적으로 검사하면 좀 더 좋을 것을 선택할 확률이 높아질 수밖에 없겠지요?
Pahalawatta 등은 비디오 기반 센서 네트워크에서의 추적 문제를 다루는데 우리가 목적으로 하는 방법과 유사한 방법을 제시하였습니다. 앞선 Zhao 논문과 다른 점은 센서가 목표물 추정을 위해 모션 세그멘테이션을 수행할 때 발생하는 초기화 비용(실시간 측정)을 고려하게 됩니다. 각 시간 단계마다 단일 센서를 선택하고 활성화하는 대신에 평균 에너지 제약 조건하에 정보 유틸리티 합이 최대화되는 센서 집합이 선택됩니다.
이를 간단히 설명하면 우선 후보를 깨우는 리더 노드가 있겠지요. 이 리더 노드는 예측된 목표물 위치에 가장 가운 노드가 될 것입니다. 리더 노드는 세트의 총 정보 획득 및 에너지 측면에서 관련 센서의 활성/비활성을 선택하게 됩니다. 목표물에 대한 데이터를 수집하고 그 위치를 더 정확하게 추정한 후, 리더노드는 후보노드를 선택하므로 좀 더 정확하겠지요. 하지만 처리노드는 이 모든 연산을 해야 하므로 큰 부하를 가져다주는 단점이 있습니다.
(3) 평균 제곱 오차(Mean Square Error, MSE) 기반의 해결책
Kaplan 등은 시스템의 음향특성을 이용하여 목표물의 도착 방향(Direction of Arrival, DOA)을 추정할 수 있는 센서들을 구비하고 있습니다.
모든 센서의 위치를 하용하여 어떤 센서 집합이 목표물의 위치를 찾기 위해 활성화되어야 하는지를 결정하는 전역 노드 선택방법을 제시하였습니다. 초기에는 두 개의 센서가 활성 집합으로 선택되고 이 두센서는 목표물과 독립적이어야 합니다. 첫 번째 활성 집합을 선택하기 위해서는 모든 센서의 조합을 시도해야 하므로 시간 복잡도가 N^2입니다. 초기 활성하 집합의 선택 이후에는 비활성화 센서 중에서 하나씩 센서를 추가하여, 탐욕 알고리즘을 사용합니다. 즉, 표적 위치에 대한 MSE를 최소화하는 것이죠. 이 방법의 경우 비활성 노드들이 품질 개선을 위해 활성화되므로 품질을 개선할 수 있지만 전역 센서들 간의 정보 소통이 이뤄져야 하며, 이는 멀티홉 라이팅이 수행된다는 뜻이고 에너지 측면에서 너무 비효율 적이므로 규모가 작은 네트워크에서만 사용 가능합니다.
이러한 단점을 파악한 Kaplan은 이전 방법의 한계를 극복하기 위해 또 다른 논문을 작성하였는데 자율 노드선택(Autonomous Node Selection, ANS)이라는 로컬 노드 선택 방법을 제시하였습니다. 이 방법에서는 선택된 노드가 현재 활성 집합에 대해 상대적으로 얼마나 유용한지에 대한 로컬 정보에만 기반하여 노드를 선택합니다. 유용선을 MSE가 고려됩니다. 이 방법 역시 초기 활성화 집합을 선택하기 위해서는 전역으로 노드들을 탐색합니다. 초기 활성 집합을 선택한 이후에는 ANS가 활성 집합의 통신 범위 내에 있는 각 노드에서 사용됩니다. 이전에 계속 광역으로 멀티홉 라이팅을 했던 거와는 달리 로컬로 집합들을 확인해 가며, 유틸리티를 계산하기 때문에 조금 더 괜찮을 수 있지만 이 방법 역시 초기에 상당히 많은 에너지가 들어가므로 작은 네트워크에서만 가능합니다. 또한 해결책을 찾기 위해 많은 수의 메시지 교환이 필요하므로 확장성에도 영향을 미치겠지요.
자 오늘은 목표물의 탐지 관점에서 어떻게 하면 잘 탐지할까 라는 주제로 포스팅해보았습니다. 각 방법마다 장단점이 있으니 논문 작성 시에 참고하시기 바랍니다. 감사합니다.



