이번에는 임무 수행 관점에서 센서를 어떻게 배치 또는 선택하는지 알아보겠습니다. 우선 이전 포스팅 관련하여 잠깐 복습을 진행하도록 하겠습니다.
1. 이전 포스팅 복습
이전 포스팅에서는 목표물을 탐지 또는 위치추적을 위해 어떻게 센서를 활성/비활성 그리고 배치시키는지 알아보았습니다. 특히 엔트로피 기반/동적 정보 기반/ 평균 제곱오차 기반의 3가지 축에서 살펴보았었죠. 엔트로피 기반에서는 탐욕 알고리즘을 사용하여 즉각적으로 엔트로피를 최소화시키는 방향으로 센서를 선택하였는데, 단일노드에 수행하는 중앙집중 방식이므로 비효일 적이며, 많은 시나리오에 적용하기 적합하지 않습니다.
동적 정보 기반은 수집된 정보에 기반하여 정보 획득을 최대로 하는 것이 목표이고 탐지 품질/추적 품질/확장성/생존성/자원 사용개선 시점에서 리더 센서를 선택하고 후보센서들 중 다음 리더센서를 선택하는 방법이었습니다. 하지만 리더노드는 다양한 판단을 해야 하므로 큰 부하를 가지게 됩니다.
평균 제곱 오차 기반은 측정값의 평균 제곱 오차를 최소화 하는것이 목표인 방법이며, 초기에 목표물의 위치를 찾기 위해 가용할 수 있는 모든 센서들을 스캐닝하고 목표물을 찾은 후 활성화 집단과 비활성화 집단을 나누게 됩니다. 그리고 활성화 집단 선택 후 탐욕알고리즘 기반으로 비활성화 집단을 하나씩 켜면서 알고리즘을 진행합니다. 이러한 방식은 멀티홉 라우팅이 수행되기 때문에 상당히 노드가 많이 걸리며, 특히 전체 스캐닝 작업은 꽤나 비효율적인 단점이 존재합니다.
2. Single Mission Assignment Schemes
이 세션에서는 임무 기반에서 한번 고려를 해보겠습니다.
시간이 지남에 따라 특정 미션을 반복수행하는 센서 네트워크에서는 어떤 임무를 어떻게 수행할지 판단하는 것이 상당히 중요합니다. 이러한 선택 방법은 목표하는 임무를 달성하기 위한 센서 노드를 선택하는 것이 중요하겠습니다. 얼마나 잘 유용성 있게 선택하느냐는 유틸리티 값으로 판단하게 됩니다. 이는 "응용 계측" 작업에 해당하는 것으로써 미션에 따라 커버리지와 추적성능을 둘 다 최적으로 끌어올리는 것입니다.
Byers와 Nasser 등은 목표를 달성하기 위해 유틸리티 함수와 감지 그리고 데이터 전송으로 인한 에너지 소비 측면에서 비용모델을 만들었습니다. 이들의 알고리즘 세트에는 센서들의 개수와 배치에 따라 얻을 수 있는 총 유틸리티 함수를 가지고 있습니다. 즉, 어떻게 배치하였을 때 어떤 유틸리티 함수가 발생하는지 미리 알고 있는 것이죠. 그렇게 함으로써 에너지 소비를 고려하여 센서 네트워크 수명을 최대화를 목표로 합니다.
Bian 등은 응용 프로그램을 만들어 센서 유틸리티 값을 지정할 수 있는 일반적인 프레임워크를 제시하였습니다. 총유틸리티를 최대화하면서 사용 가능한 에너지를 초과하지 않는 센서들의 집합을 만들고 선택하는 것입니다. 그리고 프레임워크를 사용하여 유틸리티와 센서 수명의 곱을 최대하여 가장 비용 효율적인 센서 집합을 찾는 것이기도 합니다.
위의 것들은 당연하면서도 일반적인 것입니다. 유틸리티 측면과 에너지 측면을 둘 다 최적으로 하는 것이 어디에서든 중요하게 됩니다.
3. Multiple Mission Assignment Schemes
이 세션에서는 여러 임무를 다루는 방법에 대하여 논의됩니다. 이번 논의도 위의 2항과 같이 단순 커버리지나 추적성능 관점이 아닌 응용 수준의 작업을 의미합니다. 이러한 다중 임무는 하나의 큰 작업에 속할 수도 있고, 여러 분할된 작업일 수 도입니다.
Ai와 Abouzeid는 최소한의 센서의 수로 최대한 많은 목표물을 커버하는 것을 달성하기 위해 탐욕 알고리즘을 제안하였습니다. 이 경우 센서들은 각자의 방향성을 가지고 있으며, 각 표적을 위한 커버리지는 또 다른 임무로 간주될 수 있습니다. 초기 무작위 배치 후에는 모든 목표물이 커버되지 않겠지요. 따라서 가장 많은 타깃을 커버하면서 가능한 적은 수의 센서를 활성화하기 위한 방향성 센서의 초기 방향을 변경하는 것입니다. 이를 위해 센서의 개수(n), 목표물의 개수(M), 및 센서의 가능한 방향성(P)을 매개변수로 하는 정수 프로그래밍(IP : 정수로 설정된 목적함수) 문제로 정의될 수 있습니다. 이 문제가 NP-complete임을 증명하였으며, 최적으로 해결하는 대신 탐욕 알고리즘 기반으로 한 해결책을 제시합니다.
처음에는 모든 센서가 비활성화되어 있다가 위의 알고리즘을 반복적으로 수행하여 목표물 탐지를 위한 커버리지를 달성하기 위해 비활성화된 센서를 방향성에 맞게 다시 활성화시키게 됩니다. 이렇게 되면 목표물의 커버리지가 탐욕적으로 최대화가 되게 됩니다. 이 접근 방식의 분산 구현도 가능합니다.
Mullen 등은 전체 시스템을 시장으로 모델링하여 전자상거래 개념을 센서 관리에 통합하는 장점에 대하여 연구하였습니다. 시스템은 사전에 정의된 시스템의 목표와 우선순위에 기반하여 "상품"을 생산하게 됩니다. 이 모델의 주요 구성 요소는 미션 매니저와 센서 매니저 그리고 유전 알고리즘(GA)을 사용하여 구현합니다. 미션 매니저는 소비자에 예산을 할당하는데, 이는 소비자에 관련된 다양한 임무와 그 요구사항에 기초하게 됩니다. 이 예산 값에 따라 소비자는 센서 매니저에 입찰을 제출합니다. 입찰에 기반하여 센서 매니저는 임무에 센서를 할당하게 됩니다. 이는 중앙 집중식 시스템이며, 모델의 복잡성과 GA 계산의 복잡성으로 분산 방식으로 구현하기가 매우 어렵다는 단점이 있습니다.
유전알고리즘을 잠깐 설명드리면, 생물체가 환경에 적응하면서 진화해 가는 모습을 모방하여 최적해를 찾아내는 방법입니다. 이론적으로 전역 최적점을 찾을 수 있으며, 수학적으로 명확하게 정의되지 않은 문제에도 적용 할 수 있기 때문에 매우 유용하게 사용되고 있습니다. 이를 정의하기 위해서는 4가지 개념을 알아야 합니다.
- 염색채(Chromosome) : 생물학적으로 유전 물질을 담고 있는 하나의 집합을 의미하여, 유전 알고리즘에는 하나의 해(solution)를 표현합니다.
- 유전자(Gene) : 염색체를 구성하는 요소로써, 하나의 유전 정보를 나타냅니다. 어떤 염색체가 A , B, C라면 이염색채는 각각 A, B 그리고 C을 갖는 3개의 gene가 존재합니다.
- 자손(Offspring) : 특정 시간 t에 존재했던 염색체들로부터 생성된 염색체를 t에 존재했던 염색체들의 자손이라고 합니다. 자손은 이전 세대와 비슷한 유전 정보를 갖습니다.
- 적합도(fitness) : 어떠한 염색체가 갖고 있는 고유 값으로써, 해당 문제에 대해 염색체가 표현하는 해가 얼마나 적합한지를 나타냅니다.
즉 유전 알고리즘은 t에 존재하는 염색체들의 집합으로부터 적합도가 가장 좋은 염색체를 선택하고, 선택된 해의 방향성으로 반복하면서 최적해를 찾아가는 구조로 동작하게 됩니다. 접합도를 구하는 함수는 아래와 같으며, 일반적으로 룰렛 휠 선택 방법을 채택합니다. 이는 정의된 P를 바탕으로 확률적으로 선택하는 것이 룰렛 휠 선택입니다. N은 염색체 수이고, f는 염색체 적합도를 구하는 함수인데 이 함수가 최대로 되면 되겠지요.
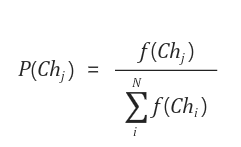
Ostwald 등은 다중 모델 센서를 사용하고 다중 임무가 동시에 일어날 수 있다고 가정합니다. 가능한 센서 구성(어떤 센서가 어떤 모드에서 작동하는지)과 임무에 대한 임무 유틸리티값을 입찰로 변환합니다. 그리고 경매알고리즘을 적용하여 최적의 센서 집합을 선택 및 결정하게 됩니다.
4. Theoretical Approaches To Sensor-Mission Assignment
센서 임무 할당에 대한 이론적 접근 방식에 대하여 설명드리겠습니다. 여러 임무들 사이에서 개별 센서를 선택하고 그 센서들을 임무에 맞게 할당도 해야 합니다. 즉, 이 문제는 개별 센서 사용의 비용과 개별 임무 간의 요구사항에 따라 가장 좋은 방식으로 센서를 임무에 할당하는 것입니다.
조금 더 상세하게는 센서 집합 S = {S1,.... Sm}와 임무 집합 M = {M1,.... Mn}이 주어졌을 때, (Si, Mj)와 같이 2분 그래프로 나타낼 수 있고 간선은 센서 Si를 임무 Mj에 할당하는 것을 의미합니다. 각 간선 (Si, Mj)는 유틸리티나 비용 값과 크게 연관이 됩니다. 예시로 아래 그림을 참조하시면 됩니다.
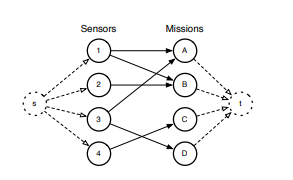
다시 말씀드리지만 목표는 가하는 제약 조건에 따라 센서를 임무에 최적으로 할당하는 것입니다. 이때, 유틸리티 최대화 및 비용 최소화가 목표가 되겠지요. 이에 따라 몇 가지 고전적인 접근 방식을 살펴보고, 최근 연구된 적근방식을 적용하여, 네트워크 플로우, 반매칭 및 온라인 매칭의 다양한 버전에 따른 센서-임무 할당 문제에 대해 설명하겠습니다.
4.1 : 플로우 기반 접근 방식
최대 플로우는 자원의 이동을 포함하는 많은 종류의 최적화 문제를 모델링하는 데 사용되고 있습니다. 앞서 제시한 센서-임무 할당 문제의 이분 그래프 표현을 고려하고, 이를 플로우 문제로 풀어보려고 합니다. 이러한 그래프의 최대 플로를 찾음으로써 최적의 센서 할당을 결정할 수 있습니다.
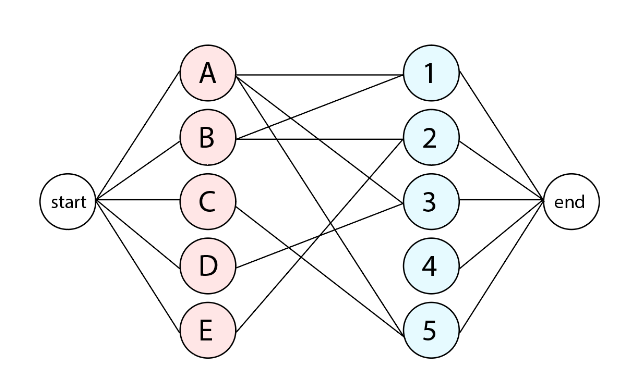
4.1.1 : 최대 플로우
최대 플로우는 각 이동 경로의 용량에 따라 얼마나 많은 자원이 출발지에서 목적지로 통과할 수 있는지를 결정하는 문제이고 이를 모델링합니다. 더 정확히 말하면, 방향 그래프 G = (V, E)가 주어지며, 여기서 V는 정점의 집합이고 E는 간선의 집합니다. 정점 집합에서는 출발지 노드 s와 목적지 노드 t라는 두 가지 특별한 노드가 포함됩니다. 각 간선은 비음수의 정수 용량과 관련되어 있으며, 이는 해당 간선을 통과할 수 있는 최대 자원량입니다. 플로우는 여러 경로의 집합으로 분해될 수 있고 간선의 용량이 일반적으로 다르기 때문에 어떤 경로를 따라 흐르는 플로우의 양은 해당 경로 상의 간선의 최소 용량으로 제한합니다. 또한, 모든 간선이 동일한 용량을 가지더라도 정점에 들어오는 간선보다 나가는 간선이 더 많을 수 있으므로 모든 간선의 용량을 모두 사용할 수 없을 때도 존재합니다. 이러한 제약조건을 고려하여, 출발지 s에서 목적지 t로의 플로우를 최대화하는 그래프 간선에 대한 실행 가능한 할당을 찾는 것이 목표입니다.
최대 플로우(유량) 알고리즘을 포드-풀커슨 알고즘으로 축약하여 좀 더 알아보겠습니다.
최대 유량 알고리즘이란 가중치가 있는 방향그래프(directed graph) G와 시작(source) 노드 s, 도착(sink) 노드 t가 주어졌을 때 각 에지에 용량(capacity)을 고려하여 s에서 t로 흘려보낼 수 있는 최대 유량(flow)을 구하는 알고리즘입니다. 전력, 수도, 통신 등 다양한 분야에서 넓게 사용되고 있습니다.
G의 에지 가중치를 용량(capacity)이라고 하며, (u, v)의 용량을 c(u, v)라고 적습니다. 용량은 항상 0 이상입니다. 노드 u와 v사이에 흐르는 유량(net flow)은 f(um v)라고 쓰며 유량은 실수치 함수(real-valued function)입니다. 최대 유량 문제에는 다음 3가지 제약 조건들이 있습니다.
- capacity constraint : f(u, v) <= c(u, v), 유량은 용량을 초과할 수 없다.
- skew symmetry : f(u, v) = - f(v, u), 앞으로나 뒤로나 동일하다
- flow conservation : 각 노드에서 유량은 새로 더해지거나 감소되지 않는다.
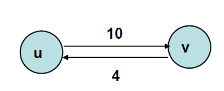
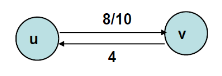
그림으로 살펴보도록 하지요. 용량 정보다 c(u, v) = 10이고 c(v, u) = 4 라면 아래 그림과 같이 표현 가능합니다.
u에서 v로 유량이 8이라면 다음과 같이 표현 가능합니다.
v에서 u로의 유량이 3이라면 다음과 같습니다.
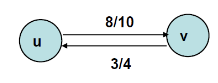
위 그래프를 양의 순 유량(positive net flow)으로 다시 표시하면 다음과 같습니다. 위 그래프를 아래처럼 바꾸는 과정을 cancellation이라고 합니다.
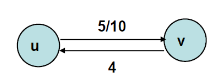
이번엔 residual networ에 대해 살펴보겠습니다. u에서 v로의 residual capacity Cf(u v)는 아래와 같이 정의합니다.
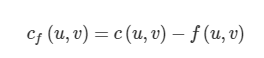
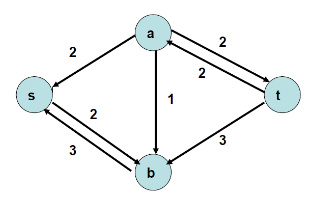
예를 들어 하단 좌측과 같이 유량 그래프 G가 주어졌을 때 G의 residual network Gf는 하단 우측과 같습니다. Gf의 에지는 cancellation 과정을 거쳐 도출된 양의 순 유량을 바탕으로 계산됩니다.
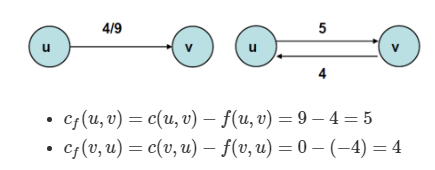
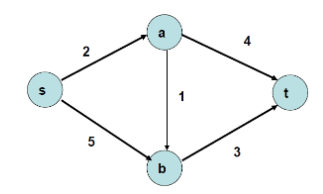
augmenting path란 residual network Gf 상에서 s에서 t로가는 경로를 말합니다. 자 그러면 포드-풀커슨 알고리즘을 살펴볼까요. 포드-폴커슨 알고리즘은 residual network를 활용하여 최대 유량을 구하는 기법입니다. 아래 그림과 같은 residual network Gf가 주어 졌다고 합니다.
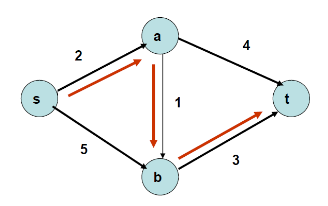
우선 깊이우선탐색(DFS)이나 너비우선탐색(BFS) 방식으로 s에서 t로 가는 경로를 하나 찾습니다. 아래 예시에서는 s, a, b t경로를 찾았죠. 이 경로를 통해 흐를 수 있는 최대 유량은 1입니다.
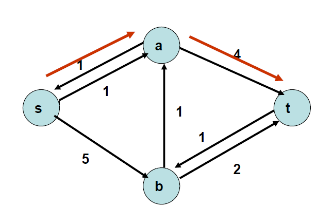
직전 단계에서 구한 경로의 반대 방향으로 최대 유량 1만큼 흘려보내는 에지를 만듭니다(augmenting path, cancellation). 다시 s에서 t로 가는 경로를 하나 찾는데 이는 s, a, t입니다. 이때 흐를 수 있는 최대 유량은 1입니다.
직전 단계에서 구한 경로의 반대 방향으로 최대 유량 1만큼 흘려보내는 에지를 만들어 줍니다. 다시 s에서 t로 가는 경로를 찾습니다. 이번에는 s, b, a, t입니다. 이경로를 통해 흐를 수 있는 최대 유량은 1입니다.
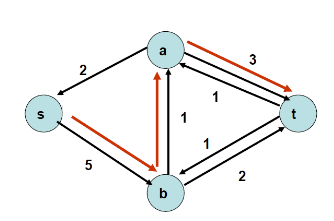
직전 단계에서 구한 경로의 반대 방향으로 최대 유량 1만큼 흘려보내는 엣지를 만들어 줍니다. 다시 s에서 t로 가는 경로는 찾는데 s, b, t입니다. 이번에 흐를 수 있는 최대 유량은 2입니다.
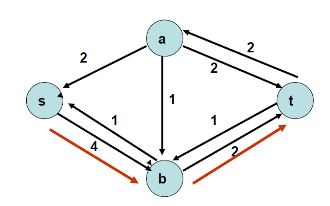
직전 단계에서 구한 경로의 반대 방향으로 최대 유량 2만큼 흘려보내는 에지를 만들어 줍니다. 다시 경로를 확인해 보니 존재하지 않습니다.
포드-풀커슨 알고리즘 수행을 종료합니다. 위 그래프는 residual network Gf이기 때문에, s에서 t로 향하는 최대 유량은 a에서 t의 2, b에서 t의 3, 이렇게 총 5가 됩니다.
자 다시 논문으로 돌아 봅시다. 논문에서 설명하길 포트-풀커슨 알고리즘은 다항 시내에 해결합니다. 이 알고리즘은 빈 플로우로 시작하고 다음과 같이 진행합니다. 출발지 s에서 t까지 아직 사용가능한 용량을 가진 경로가 그래프에 존재하는 한, 경로 전체의 사용량을 가능한 한 높게 증가시킵니다. 남아있는 증가 경로가 없을 때까지 이 과정을 반복한 후 멈추게 됩니다. 주요한 점은 포드-풀커슨에 의해 반환된 최대 플로우는 정수로 구성되며, 간선을 통과하는 플로우는 정수라는 뜻입니다.
표준 최대 플로우 문제에서는 각 간선의 사용량이 상한선(용량)만 가지고 있고 하한선은 존재하지 않습니다. 일부 응용 프로그램에서는 하한선을 포함할 수 있으나 이러한 경우에는 간단히 포드-풀커슨을 적용할 수 없습니다. 이유는 빈 플로우가 실행 가능하지 않을 수 있기 때문입니다. 이를 해결할 수 있는 방법도 있는데 간선에 상한선과 하한선이 있는 그래프가 주어진 경우, 이를 일반적인 최대 플로우 그래프로 변환할 수 있습니다. 이 그래프는 상한선만 가지고 있지만, 원래 그래프의 상한선과 다를 수 있습니다. 빈 플로우는 새로운 그래프에서 실행 가능하므로 최대 플로우를 찾을 수 있으며, 이를 원래 그래프에서 실행 가능한 플로우로 다시 변환할 수 있습니다.
4.1.2 : 최소 비용 최대 플로우
최대 플로우 문제의 경우, 최대 플로우 설루션은 유일하지 않을 수 있습니다. 간선에 용량과 단위 비용이 연관되는 경우, 최소 총비용의 최대 플로우를 찾는 최소 비용 최대 플로우 문제는 유일한 최대 플로우를 찾는 것입니다. 이러한 문제의 정수 솔루션을 다항 시간 내에 찾기 위한 고전적인 알고리즘이 존재합니다.
운송 문제는 상품의 최소 비용 운송을 모델링하는 문제입니다. 우리에게는 소스와 터미널의 가중치가 있는 이분 그래프가 주어집니다. 간선 가중치 wij는 Si에서 Mj로의 상품 운송의 단위 비용입니다. 각 소스는 공급량 Pi를 가지고 각 터미널은 수요량 Dj를 가지고 있습니다. 사용 가능한 공급량을 사용하여 모든 수요를 충족하는 최소 비용 방법을 찾고자 하는 것입니다. 이 문제는 최소 비용 최대 플로우로 쉽게 축소가 가능합니다. s와 t를 그래프에 추가하여 각 간선(s, Si)의 용량을 Pi로 설정하고, 각 간선 (Mi, t)의 용량을 수요량 Dj로 설정하면 됩니다.
이제 센서-미션 할당에 대한 보다 정교한 모델을 설명드리겠습니다. 여기서 유일한 센서-미션할당(센서는 하나의 미션에만 할당될 수 있음.)을 요구하되, 미션의 요구 사항을 단순히 미션이 필요로 하는 센서의 수로 완하시켜 계산합니다(그러러면 모든 조건들이 미리계산 되어야겠지요). 각 가능한 센서-미션에는 비용값이 존재하게 됩니다. 각 미션에 요구되는 센서 수를 충족시키기 위해 센서를 고유하게 미션에 할당합니다. 최적화 문제는 총비용을 최소화하는 실행 가능한 할당을 찾는 것입니다. 이 방식은 단순히 모든 소스 공급량이 1인 운송으로 가정하게 됩니다.
4.2 : 매칭과 세미매칭
센서-미션 할당을 이분 매칭 문제로 표현하는 방법들을 살펴보겠습니다. 센서와 미션을 나타내는 두 개의 노드 집합에 대한 가장 큰 크기 또는 가장 큰 가중치를 갖는 매칭을 찾고자 합니다. 세미-매칭 문제에서는 한쪽의 노드가 여러 번 사용될 수 있습니다. 이는 일반적으로 여러 센서가 동일한 미션에 할당될 수 있다는 뜻입니다.
이분 매칭 문제는 다음과 같이 정의될 수 있습니다. 이분 그래프가 주어지고 노드 집합 A와 B가 있다고 가정하면, 그래프에서 최대 매칭을 찾습니다. 최대 매칭이란, 선택된 에지들의 집합 중에서 가장 크기가 큰 것을 의미하며, 선택된 두 에지가 동시에 하나의 끝점을 공유하면 안 됩니다. 더 정교한 알고리즘들이 있지만 이 문제를 다항 시간 내에 해결하는 간단한 방법 중 하나는 최대 플로우로 축소하는 것입니다.
이분 매칭 인스턴스를 최대 유량 문제로 변환하기 위해서는 단순히 새로운 노드 s를 A의 각 집합에 연결하고, 새로운 노드 t를 B 집합에 가리키게 합니다. 이때 모든 존재하는 에지의 용량은 1로 설정합니다. 그런 다음 최대 유량 알고리즘을 실행하여 정수 해를 생성합니다. 모든 에지의 용량이 1이므로, 결과적인 유량으로부터 매칭을 얻어낼 수 있습니다.
가중치가 있는 이분 매칭에서는, 음이 아닌 가중치를 갖는 두 노드 집합 A와 B의 이분 그래프가 주어집니다. 최대 가중치 매칭, 즉 가중치의 합이 최대인 에지들의 부분 집합을 찾는 것이죠. 다시 한번 선택된 두 에지가 동시에 하나의 끝점을 공유하면 안 됩니다. 유일하기 때문이죠. A와 B가 같은 크기가 되도록 추가적인 노드를 도입하고, 모든 누락된 에지의 가중치를 0으로 설정할 수 있습니다. 가중치는 음이 아니므로, 모든 최대 가중치 매칭은 완전 매칭이 됩니다. 모든 에지 가중치 Wij를 cij=W-wij로 바꾸면(여기서 W는 모든 가중치의 최댓값), 최소화 문제가 됩니다.
이분 세미-매칭은 일반적인 이분 매칭과 유사하지만 매칭 제약이 완화됩니다. A의 두 에지가 하나의 끝점을 공유하지 않는 에지들의 부분 집합을 찾습니다. 기수 및 가중치 설정에 대해 문제를 정의할 수 있으며, 앞서 언급한 최대 유량으로의 축소를 통해 문제를 해결할 수 있습니다.
가중치와 비가중치 매칭 모델은 센서 네트워크에 적용할 수 있습니다. 센서와 미션의 이분 그래프가 주어지면, 에지(Si, Mj)의 존재는 Si가 Mj에 어떤 서비스를 제공할 수 있다는 것을 뜻합니다. 타당한 해결책에서 각 센서는 최대 하나의 미션에 할당되게 됩니다.
가중치 반매칭 모델도 센서 할당 문제를 해결하는 데 사용됩니다. 센서와 미션의 가중치 이분 그래프가 주어지며, 각 에지(Si, Mj)는 센서가 미션에 대해 얼마나 유용한지를 나타내는 유틸리티 값과 관련이 있습니다. 이 모델에서의 동기는 각 미션은 커버되기를 원하며, 다른 센서들은 그것을 커버할 수 있지만 어떤 센서들은 미션에 대해 더 나은 품질의 정보를 얻을 수 있습니다. 그리고 각 센서는 하나의 미션에 할당될 수 있습니다. 이 방식은 즉시 가중치 반매칭으로 축소될 수 있지만, 매우 단순한 모델이기는 합니다. 가중치 비가중치 버전의 매칭 문제는 Kowk 등이 센서-미션 할당의 문맥에서 연구하였습니다.
4.3 : 온라인 매칭과 반매칭
앞선 두 섹션에서는 전체 미션 집합이 한 번에 주어지고 오프라인 방식으로 문제를 해결한다고 하였습니다(동기화). 그러나 실제 현장에서는 미션들이 서로 다른 시간에 도착하게 됩니다. 이 섹션에서는 순차적인 온라인 모델을 설명합니다. 각각의 미션이 도착할 때마다 우리는 미션에 센서를 할당해야 합니다. 미래의 미션에 대한 정보 없이 이 결정들은 변경할 수 없습니다. 한번 센서가 할당되면, 이후의 어떤 미션에도 재할당 될 수 없습니다. 대체 모델에서는 센서 재할당을 허용하거나 그에 대한 비용을 부과하지만, 이 논문에서는 그런 것을 고려하지 않겠습니다.
Kalyanasundaram과 Pruhs는 B-Matching 문제의 온라인 비가중치 버전을 연구하고 최적의 결정론적 알고리즘을 제시합니다. B-Matching에서는 서버와 요청을 포함하는 이분 그래프에 존재하는 에지들의 부분집합을 선택합니다. 에지의 존재는 서버가 요청을 처리할 수 있다는 것을 뜻하지요. 각각의 요청은 서버에 할당되어야 하며, 각 서버는 최대로 b개의 요청을 처리할 수 있습니다. 온라인 버전에서는 요청들과 그들의 모든 에지가 한 번에 하나씩 도착합니다. 각 요청은 즉시 서버에 할당되거나 거부될 수 있습니다.
이때 BALANCE라는 간단한 알고리즘을 제시하는데, 이 알고리즘은 b가 클 경우 경쟁률이 1-1/e에 가까워집니다. 각각의 요청 r에 대해 BALANCE는 r의 이웃 중에서 지금까지 가장 적게 사용된 서버를 선택합니다. 서버의 사용 수준은 그 이름에서 알 수 있듯이 균형을 유지합니다.
센서와 미션 문제에 이를 적용하는 한 가지 방법은 각 센서가 한 번에 최대 b개의 미션을 처리할 수 있다고 가정하는 것입니다. 이러한 제한이 주어지면, 미션들이 온라인으로 도착하는 상황에서 최대 매칭을 찾습니다.
Kalyanasundaram과 Pruhs는 온라인 매칭 문제의 가중치 버전인 온라인 최소 매칭(Min-Matching, 에지 가중치 최소화)과 온라인 최대 매칭(Max-Matching, 에지 가중치 최대화)을 연구하였습니다. 이 둘 모두 일반적인 경우 적용이 어렵기 때문에 삼각 부등식을 만족하는 메트릭 공간에 제한하여 연구합니다. 이때, 가중치는 서버의 위치와 요청 사이의 거리로 해석하게 됩니다. 여기서 k개의 서버를 r개의 요청과 매칭시켜서 총 이동 거리를 최소화해야 합니다. 최소 매칭은 꽤 어렵다는 것이 이미 밝혀졌습니다. 저자들은 PERMUTATION이라는 최적 경쟁알고리즘을 제시하는데, 이 알고리즘의 경쟁률은 1/2k - 1로, 노드가 2k 개인 겨우 에 최적입니다. 최대 매칭 문제에 대해서는, 저자들은 1/3 경쟁률을 가진 최적의 탐욕 알고리즘을 제시합니다.
그러나 몇 가지 유틸리티가 0인 에지를 포함하는 센서-미션 이분 그래프는 삼각 부등식 적용이 어렵기 때문에, Max-Matching 적용이 어렵습니다. 센서 네트워크는 물리적(메트릭) 세계에서 존재하지만, 센서의 유틸리티는 거리에 기반한 부분이기도 하고 정보의 달리티와 같은 다른 요소도 영향을 미치므로 어렵다고 표현하고 있습니다.



