웹 크롤링 관련 강의를 마쳤으나, 추가 강의를 하도록 하겠습니다. 웹 크롤링이 안될 때 해결법을 말씀드리겠습니다. 당연한 거지만 네이버 같은 웹사이트에서 자신만의 데이터를 못 가져가게 막아 놓았더군요.
1. 기존 강의 복습과 문제점 설명
아래 코드를 확인해 보시면 urlopen으로 간단히 우리가 원하는 사이트에서 원하는 값을 가져오는 것을 말씀 드렸습니다. 이 부분은 네이버 첫 화면일 경우 가능하고 세부적으로 들어가 더 디테일한 값을 가져오려고 할 때 애러가 발생하게 됩니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
response = urlopen("https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%ED%99%98%EC%9C%A8/") # 크롤링하고자하는 사이트
soup = BeautifulSoup(response, "html.parser") # html에 대하여 접근할 수 있도록
value = soup.find("span", {"class": "spt_con dw"})
print(value)
value2 = value.text.split() # split(구분좌)
print(value2)
a = value2[0][2:10] # 환율값
b = value2[1][4:11] # 증가/하락
c = value2[2][1:7] # 증가/하락 비율
print(a)
print(b)
print(c)아래 그림처럼 인버스의 자세한 값을 가져오려고 하면 반드시 에러가 발생합니다. 그 이유는 네이버가 웹 스크레핑을 차단해서 파이썬을 통해 urlopen()으로 생으로 접속하게 되면 해당 주소가 없는 주소라고 결과를 보내기 때문입니다.

이러한 차단 방식은 http 패킷 해더에 브라우저 정보(User-Agent)가 존재하는지 확인하는 방식입니다. 따라서, 우리는 urlopen() 방식이 아닌 http 요청 패킷에 웹브라우저 정보를 보내주어야 원하는 정보를 얻어 올 수 있습니다(네이버는 대규모 크롤링을 방지하기 위해 최소한의 방어막을 만들어 놓았습니다).
2. 해결 방법 : 패킷 해더에 Uesr-agent 정보 삽입하기
해결방법은 생각보다 간단합니다. 우선 위에서 사용하였던 urlopen() 함수는 더 이상 사용하지 않습니다. 우선 코드를 확인해 보겠습니다.

(1) 관련 함수를 가져 옵니다. 혹시 설치가 되지 않으신 분들은 pip install bs4와 pip install requests를 하십시오.
(2) save 1 = [] : save1에 우리가 크롤링 데이터를 전부 저장합니다.
(3) 가장 주요한 부분입니다.
- url : url 주소를 반드시 f" 여기에 입력하세요 "
- req : 해더 생성 부분입니다. headers에 User-agent는 Mozila/5.0으로 설정하였습니다. 원칙적으로는 더 디테일하게 적어야 되나 Mozila/5.0만 적으셔도 됩니다. 혹시 디테일하게 적으실 분들은 아래 더 포스팅해 놓겠습니다.
우선 링크된 사이트에 접속하세요 : 링크
사이트에 접속하시면 아래와 같이 화면이 뜹니다. 그러면 아래 빨간색 네모칸 부분을 복사 붙여 넣기 하시면 되고 붙여 넣기 할 부분은 Mozila/5.0에 넣으시면 됩니다. 이렇게 하시면 완벽합니다.
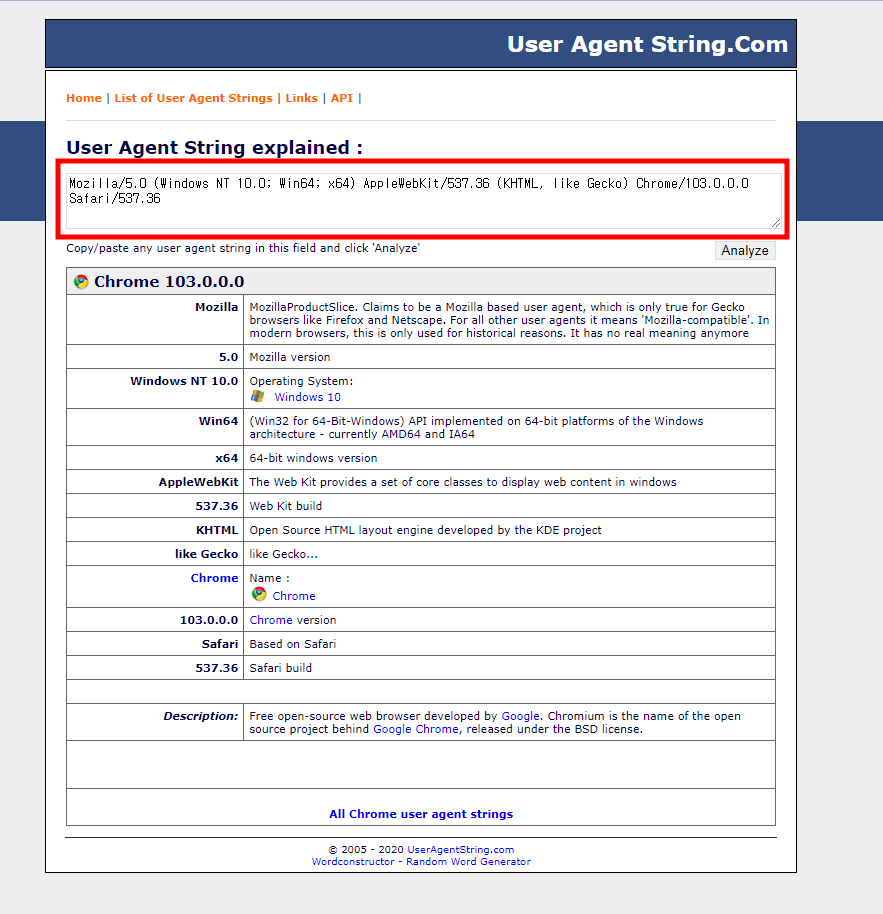
- soup : 기존 강의와 동일하여 원하는 사이트에서 lxml로 데이터를 가져옵니다.
(4) value_a = soup.find_all("span", {"class": tah p11}) : 우리가 크롤링한 데이터 soup 에서 원하는 부분을 찾습니다. find를 하시면 1개의 값만 찾고 find_all을 하시면 관련 모든 데이터를 가져옵니다. 그리고 아래 그림과 같이 span 태그의 tah p11 클래스 데이터를 모두 가져와서 가공합니다.

(5) 가져온 데이터를 단순히 전시하는 것입니다.
3. 코드 및 결론
네이버/다움/구글 등 다양한 사이트에서는 자신만의 노하우로 단순 크롤링하지 못하게 막아 두었습니다. 하지만 해더에 User-agent만 넣는다면 그러한 문제는 쉽게 해결될 수 있습니다. 아래 코드를 공유해 드리니 많이들 참고하시기 바랍니다. 감사합니다.
from bs4 import BeautifulSoup # 크롤링 사이트의 값을 가져오는 함수
import requests
save1 = [] # 관련 값 다 저장하기
code = '530053'
url = f"https://finance.naver.com/item/frgn.naver?code={code}"
req = requests.get(url, headers={'User-agent': 'Mozilla/5.0'})
soup = BeautifulSoup(req.text, "lxml") # html에 대하여 접근할 수 있도록
value_a = soup.find_all("span", {"class": "tah p11"})
for title in value_a:
save1.append(title.get_text())
print(save1)
a9 = save1[0] # 풋 값
c9 = save1[2] # 풋 증가량
print(a9)'주식 자동매매 강의 > 중급반(시황 및 차트 구현)' 카테고리의 다른 글
| [주식자동매매] 분할 매수/매도 코딩하기(5), 종목명/종목코드 가져오기 (6) | 2022.07.14 |
|---|---|
| [주식자동매매] 분할 매수/매도 코딩하기(4), 감시가격/매수수량 입력 GUI 초기화 하기 (10) | 2022.07.14 |
| [주식자동매매] 분할 매수/매도 코딩하기(3), GUI 전시하기 (2) | 2022.07.09 |
| [주식자동매매] 분할 매수/매도 코딩하기(2), GUI 만들기 (14) | 2022.07.07 |
| [주식자동매매] 분할 매수/매도 코딩하기(1), 개념 설명 (4) | 2022.07.05 |



